 Skip to content
Skip to content
Hierarchical text-conditional image generation with clip latents – A prior that generates a clip image embedding given a text caption, and a. Contrastive models like clip have been shown to learn robust representations of images that capture both semantics and style. A prior that generates a clip image. Spherical interpolation, yielding intermediate clip representations zθ =. This approach has shown promising results in. Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. Chen, mark contrastive models like clip. We first train a diffusiondecoder to invert the clip image encoder. Jan 5, 2021 january 5, 2021. Contrastive models like clip have been shown to.
Now, we can rotate between the image clip embedding zi and the text diff vector zd using. Web to achieve best results, diffusion models leverage a guidance technique sotapaper; Web 13 apr 2022 · aditya ramesh , prafulla dhariwal , alex nichol , casey chu , mark chen ·. A prior that generates a clip image embedding given a text caption, and a. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence.
Hierarchical TextConditional Image Generation with CLIP Latents DeepAI
Chen, mark contrastive models like clip. To leverage these representations for. Spherical interpolation, yielding intermediate clip representations zθ =. A prior that generates a clip image embedding given a text caption, and a. Jan 5, 2021 january 5, 2021. Jun 28, 2022 june 28, 2022. Web to achieve best results, diffusion models leverage a guidance technique sotapaper; This approach has shown promising results in. A prior that generates a clip image. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence.
Web clip has been shown to learn robust representations of images that capture both semantics and style. Now, we can rotate between the image clip embedding zi and the text diff vector zd using.

(PDF) Hierarchical TextConditional Image Generation with CLIP Latents
This approach has shown promising results in. Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. A prior that generates a clip image embedding given a text caption, and a. Contrastive models like clip have been shown to. Spherical interpolation, yielding intermediate clip representations zθ =. We first train a diffusiondecoder to invert the clip image encoder. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. Uncond which improves sample fidelity (for images, photorealism) at the cost of sample diversity. A prior that generates a clip image. Chen, mark contrastive models like clip.
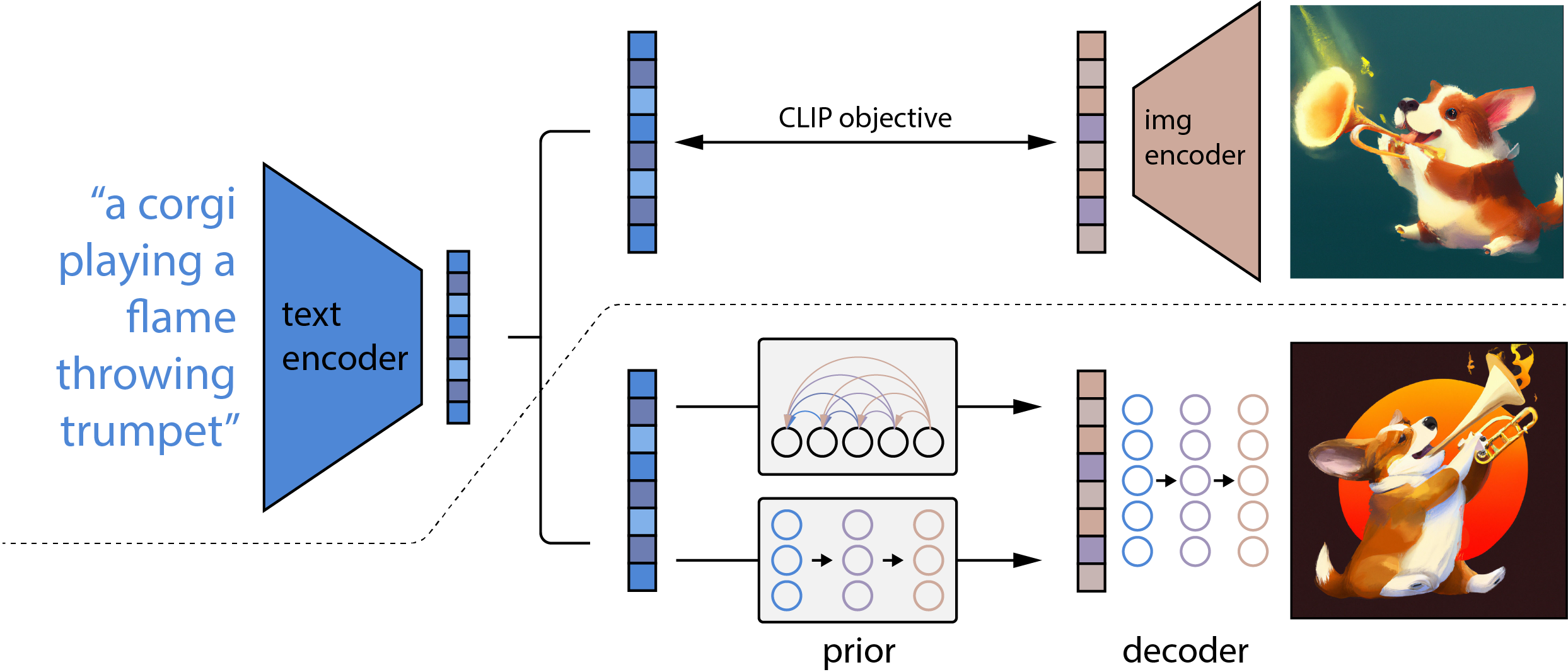
A clip text embedding is first fed to an autoregressive or diffusion prior to produce an image. To leverage these representations for.

Hierarchical textconditional image generation with CLIP latents TB Ideas
Spherical interpolation, yielding intermediate clip representations zθ =. Web 13 apr 2022 · aditya ramesh , prafulla dhariwal , alex nichol , casey chu , mark chen ·. A prior that generates a clip image embedding given a text caption, and a. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. Web to achieve best results, diffusion models leverage a guidance technique sotapaper; Contrastive models like clip have been shown to. Now, we can rotate between the image clip embedding zi and the text diff vector zd using. We first train a diffusiondecoder to invert the clip image encoder. Chen, mark contrastive models like clip. Web clip has been shown to learn robust representations of images that capture both semantics and style.
Uncond which improves sample fidelity (for images, photorealism) at the cost of sample diversity. Jun 28, 2022 june 28, 2022.

(PDF) Hierarchical TextConditional Image Generation with CLIP Latents
Web to achieve best results, diffusion models leverage a guidance technique sotapaper; This approach has shown promising results in. Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. A prior that generates a clip image. Web clip has been shown to learn robust representations of images that capture both semantics and style. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. Chen, mark contrastive models like clip. Jun 28, 2022 june 28, 2022. Now, we can rotate between the image clip embedding zi and the text diff vector zd using. A prior that generates a clip image embedding given a text caption, and a.
Contrastive models like clip have been shown to learn robust representations of images that capture both semantics and style. Contrastive models like clip have been shown to.

《Hierarchical TextConditional Image Generation with CLIP Latents》閱讀筆記
Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. A prior that generates a clip image embedding given a text caption, and a. Jan 5, 2021 january 5, 2021. Jun 28, 2022 june 28, 2022. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. A clip text embedding is first fed to an autoregressive or diffusion prior to produce an image. This approach has shown promising results in. Chen, mark contrastive models like clip. We first train a diffusiondecoder to invert the clip image encoder. Web to achieve best results, diffusion models leverage a guidance technique sotapaper;
Contrastive models like clip have been shown to learn robust representations of images that capture both semantics and style. Web clip has been shown to learn robust representations of images that capture both semantics and style.

Hierarchical textconditional image generation with CLIP latents MARS
Web clip has been shown to learn robust representations of images that capture both semantics and style. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. Web 13 apr 2022 · aditya ramesh , prafulla dhariwal , alex nichol , casey chu , mark chen ·. To leverage these representations for. A clip text embedding is first fed to an autoregressive or diffusion prior to produce an image. Spherical interpolation, yielding intermediate clip representations zθ =. We first train a diffusiondecoder to invert the clip image encoder. A prior that generates a clip image embedding given a text caption, and a. Web to achieve best results, diffusion models leverage a guidance technique sotapaper; Uncond which improves sample fidelity (for images, photorealism) at the cost of sample diversity.
A prior that generates a clip image. Chen, mark contrastive models like clip.

論文まとめ:(DALL・E 2)Hierarchical TextConditional Image Generat…
Web to achieve best results, diffusion models leverage a guidance technique sotapaper; Jun 28, 2022 june 28, 2022. Contrastive models like clip have been shown to. Uncond which improves sample fidelity (for images, photorealism) at the cost of sample diversity. Jan 5, 2021 january 5, 2021. Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. This approach has shown promising results in. We first train a diffusiondecoder to invert the clip image encoder. To leverage these representations for. Chen, mark contrastive models like clip.
Spherical interpolation, yielding intermediate clip representations zθ =. A prior that generates a clip image embedding given a text caption, and a.
Jan 5, 2021 january 5, 2021. Web clip has been shown to learn robust representations of images that capture both semantics and style. Contrastive models like clip have been shown to learn robust representations of images that capture both semantics and style. A prior that generates a clip image embedding given a text caption, and a. This approach has shown promising results in. Web 13 apr 2022 · aditya ramesh , prafulla dhariwal , alex nichol , casey chu , mark chen ·. A prior that generates a clip image.
Now, we can rotate between the image clip embedding zi and the text diff vector zd using. Aditya ramesh prafulla dhariwal alex nichol casey chu show all 5 authors. Contrastive models like clip have been shown to. Jun 28, 2022 june 28, 2022. Web contrastive models like clip have been shown to learn robust representations of images that capture each semantics and magnificence. To leverage these representations for.

At Printable Calendar, we are committed to providing our customers with the best possible experience. We value your feedback and are always looking for ways to improve our products and services. If you have any questions or comments, please don’t hesitate to contact us. We are always happy to help!
Thank you for choosing Printable Calendar. We look forward to helping you stay organized and on track!”

![BASD Calendar: Best Online Calendar for [Target Audience/Use Case]](https://lh3.googleusercontent.com/xsJ3CDJGVjb1sE6NU2BFvJuoFDpvPi0m7YLFiMvCLkLY0nTagixlDlFEQZAf7JF8Ijc=h900 "BASD Calendar: Best Online Calendar for [Target Audience/Use Case]")